Author: The FourthBrain Team • November 4, 2022

In this post, we’ll highlight the key takeaways from the FourthBrain-hosted event on Building NLP Applications with Transformers presented by Julien Simon, Chief Evangelist at HuggingFace, and hosted by Greg Loughnane, Head of Product and Curriculum at FourthBrain. If you’d like to follow along with the hands-on demo or explore other interesting tutorials created by Julien and the HuggingFace team, feel free to download the notebooks from the following GitLab repo.

We’ll answer the following questions in this post:
1. What is HuggingFace and what problem does it solve?
2. How can I leverage HuggingFace to more quickly develop state-of-the-art Transformer based NLP, Computer Vision, and Speech processing applications?
3. Where can I go to learn more about FourthBrain, HuggingFace, and future events like this?
What is HuggingFace and what problem does it solve?
HuggingFace is on a journey to advance the open-source machine learning ecosystem and democratize good machine learning, one commit at a time. They have built the fastest-growing, open-source, library of pre-trained models in the world with over 100M+ installs, 65K+ stars on GitHub, and over 10 thousand companies using HuggingFace technology in production, including leading AI organizations such as Google, Elastic, Salesforce, Algolia, and Grammarly.

Julien opened up the session with a brief overview of the modern history of Deep Learning techniques such as in 2012 when AlexNet, a GPU-implemented CNN model designed by Alex Krizhevsky, wins Imagenet’s image classification contest with an accuracy of 84%. It was a huge jump over the 75% accuracy that earlier models had achieved and that triggered a new deep learning boom globally. In the Deep Learning 1.0 era, it was time-consuming and costly to acquire large enough datasets to train purpose-built deep learning systems to achieve meaningful results in a production environment. In the Deep Learning 2.0 era, transfer learning has become much more ubiquitous and pre-trained models with high-performing and generalizable architectures are much more readily available to machine learning practitioners requiring less training data to fine-tune models on task-specific objectives while still maintaining good performance in deployment settings.

How can I leverage HuggingFace to more quickly develop state-of-the-art Transformer based NLP, Computer Vision, and Speech processing applications?
After the brief overview of modern Deep Learning, Julien transitioned to the graphic below which depicts an Agile framework for developing machine learning projects in the HuggingFace ecosystem. The hands-on demonstration portion of the event focused more heavily on the Datasets and Models blocks of this workflow but it’s important to note that HuggingFace is pursuing clean integrations with large cloud providers such as AWS and Microsoft.
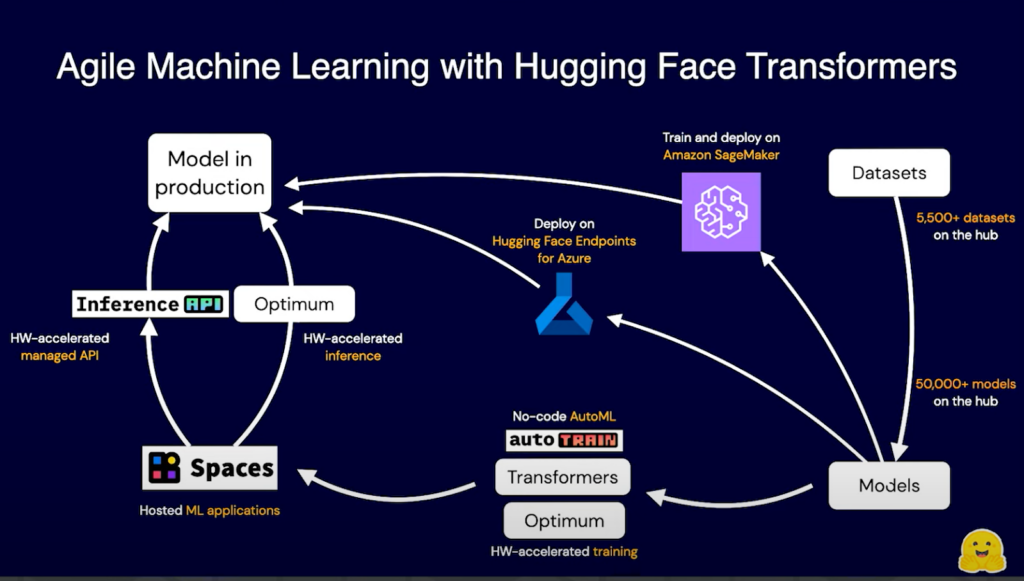
Now, the first step in any Machine Learning project is to clearly state the business problem that we’re trying to solve. The use case that Julien focused on in the demo was to assume that we work for a shoe retailer who wants to better understand the voice of their customers by scoring reviews left on their website for the sentiment. With the business problem defined, we can head out to the HuggingFace hub to begin researching potential models and datasets for our use case.
The HuggingFace Hub is a platform with over 68K models, 9K datasets, and 8K demos in which software engineers can easily collaborate in their ML workflows. The Hub works as a central place where anyone can share, explore, discover, and experiment with open-source Machine Learning. A few advantages of the Hub are as follows:
- Free model or dataset hosting
- Built-in file versioning, even with very large files, thanks to a git-based approach
- Hosted inference API for all models publicly available
- In-browser widgets to play with the uploaded models
- Fast downloads for improved collaboration regardless of time zone
- Usage stats, monitoring, and more features are being added regularly
In navigating the Hub, Julien starts by looking for a good pre-trained model:

All models uploaded to the Hub are tagged based on the downstream task that the given model is able to support (i.e. image classification, question answering, text classification, text summarization, etc.).
Next, we search for datasets that have been uploaded to the Hub that may be suitable for our task and come across a massive Amazon US reviews dataset which consists of ~150 million reviews on Amazon dating back to 1995. The data set has also been subdivided into 46 categories (i.e. apparel, automotive, baby, etc.) and luckily shoes is a category so just like that we’ve found a dataset of ~4.3 million shoe reviews that we can use to train our transformer model.

One of the best aspects of the Hub whether you are searching for datasets or models is the level of documentation that goes into the Model and Dataset cards. In the Dataset card you are able to:
- Preview the data in-browser
- Read a brief and/or detailed description of its origin and any assumptions that were made when curating the dataset
- Review memory requirements
The Model card is even more thoroughly documented in that users are provided with:
- Summary of the model
- Intended uses
- How to use the model with code examples
- Limitations and potential bias
- A hosted inference API to test the model on the task that it was trained on
- Training data used
- Model training procedure
The Datasets and Model features within the Hub are designed to ensure that machine learning in the HuggingFace ecosystem is reliable, reproducible, and performant. If you’re interested in a few additional resources that may be helpful when searching for Datasets, I’d recommend checking out the following:
- Google’s Datasets Search Engine
- Kaggle Datasets
- AWS Open Data Registry
- Microsoft Azure Open Datasets
- UCI Machine Learning Repository
- Awesome Public Datasets GitHub repository
- DrivenData competition datasets
Now that we have a dataset and model selected, Julien walked us through using the transformers library to train the model locally or in the cloud as well as:
- Browse models on the Hugging Face Hub,
- Test models with the inference widget,
- Fine-tune a Hugging Face Transformer with the Trainer API from the transformers library,
- Create a model repository with the Hugging Face CLI,
- Write a model card,
- Load a model with the Pipeline API, and predict with it,
- Deploy a model on the Hugging Face Inference API, and predict with it.
If you’d like to follow along with this section of the demo, check out the 02_train_deploy.ipynb notebook in the GitLab repo.
Lastly, Julien demonstrated how to showcase your models with HuggingFace Spaces. The 05_Spaces.ipynb notebook covers the following topics:
- Write a simple Gradio application to showcase your model,
- Deploy the application to Spaces and test it.
Due to timing constraints, Julien wasn’t able to walk through a few additional notebooks that he had developed in the GitLab repo for this demo but a summary of those is provided below.
Training models automatically with AutoTrain (02_AutoTrain)
- Launch an AutoML job with AutoTrain,
- Work with AutoTrain datasets and models.
Logging, part 1: tracking training jobs with MLflow (02_train_mlflow)
- Enabling MLflow with the transformers library,
- Logging metrics and parameters,
- Storing MLflow logs on the Hub,
- Visualizing metrics in a notebook and in the MLflow UI.
Logging, part 2: tracking training jobs with TensorBoard (02_train_tensorboard)
- Enabling TensorBoard with the transformers library,
- Logging metrics and parameters,
- Storing TensorBoard logs on the Hub,
- Visualizing in the TensorBoard UI and on the model page.
Evaluating models, part 1: scoring models with built-in metrics in the Evaluate library (02_evaluate)
- Listing metrics available in the library,
- Computing metrics for text classification models: accuracy, F1, MSE.
Accelerating inference, part 1: Hugging Face Optimum and ONNX optimization (03_optimize_onnx)
- Export a model to ONNX format,
- Optimize an ONNX model with ,
- Quantize an ONNX model with Optimum.
Accelerating inference, part 2: Hugging Face Optimum and the Intel Neural Compressor (03_optimize_inc_quantize)
- Quantize a Transformer model with Optimum Intel,
- Look at model layers and see how operators have been replaced by their quantized equivalent.
Working with models, part 2: training and deploying at scale on Amazon SageMaker (04_SageMaker)
- Adapt your training script to run on SageMaker,
- Use the SageMaker SDK to launch a training job,
- Use the SageMaker SDK to deploy a model on a SageMaker Endpoint (instance-based and serverless),
- Use the SageMaker SDK to predict with an endpoint.
Where can I go to learn more about FourthBrain, HuggingFace, and future events like this?
Backed by Andrew Ng’s AI Fund FourthBrain helps you take your ML career to the next level in our cohort-based courses which are designed to accelerate your learning so that you can apply the latest and greatest ML approaches to your next AI project by learning best practices and state-of-the-art tools from first principles so you’ll be ready to make a bigger impact in your current role or in your new job.
If you are interested in learning more about the Machine Learning programs at FourthBrain, check out our website for the next cohort start dates and follow us on LinkedIn to be notified of future events like this one.
Lastly, if you would like to learn more about Transformers and the HuggingFace ecosystem, I would highly recommend the free HuggingFace course:
Here is a brief overview of the course from the authors:

The course consists of 12 chapters (the final 3 are in development):
- Chapters 1 to 4 provide an introduction to the main concepts of the 🤗 Transformers library. By the end of this part of the course, you will be familiar with how Transformer models work and will know how to use a model from the Hugging Face Hub, fine-tune it on a dataset, and share your results back on the Hub!
- Chapters 5 to 8 teach the basics of 🤗 Datasets and 🤗 Tokenizers before diving into classic NLP tasks. By the end of this part, you will be able to tackle the most common NLP problems by yourself.
- Chapters 9 to 12 go beyond NLP and explore how Transformer models can be used to tackle tasks in speech processing and computer vision. Along the way, you’ll learn how to build and share demos of your models, and optimize them for production environments. By the end of this part, you will be ready to apply 🤗 Transformers to many different machine learning problems!
To get the most out of the course, the following pre-requisites are recommended:
- Strong knowledge of Python
- Recommend taking an introductory deep learning course first such as fast.ai’s Practical Deep Learning for Coders or one of the programs developed by DeepLearning.AI
- Does not expect prior PyTorch or TensorFlow knowledge, though some familiarity with either of those frameworks will help
After you’ve completed this course, check out DeepLearning.AI’s Natural Language Processing Specialization, which covers a wide range of traditional NLP models like naive Bayes and LSTMs that are well worth knowing about!